Beyond the Browser, Within the Browser: Browser APIs for an AI-Native Approach


Beyond the Browser: Exploring Potential AI Architectures
Browser-native AI has been inching forward lately, and with it comes a wave of sometimes overblown expectations. While we've moved past the era of hacky demo scripts bumping against IndexedDB limits, we should temper our excitement with healthy skepticism. Could browsers really evolve into orchestration engines? Will we see agents communicating across tabs? Could models prefetch themselves? Might runtimes in JavaScript, Zig, and WebAssembly all work together seamlessly? Off the grid? These questions are fascinating, but also raise concerns about complexity.
What follows isn't a declaration of how things should be, but rather a collection of ideas worth exploring—a speculative journey through possibilities for browser-based AI architectures. Each approach represents an avenue of research with both promise and limitations. The code samples aren't production-ready solutions; they're starting points for experimentation. Consider this field notes from the frontier, complete with the questions and challenges that might arise along the way.
1. SharedWorker Architecture: A Tempting but Unproven Approach
In theory—and theory is the operative word here—a single, persistent model instance could run in the background, shared across every tab in a browser session. No redundant downloads, no repeated initialization of LLM weights for each reload. SharedWorker seems like it could enable this, but there are reasons to be cautious.
SharedWorkers technically maintain a lifetime that spans connected browsing contexts, which sounds perfect for AI workloads. Initialize a 7B parameter model once, then serve inference requests across multiple tabs without redundant initialization. But there are potential inconsistencies across browsers to consider. Chrome might kill workers under memory pressure without warning, Firefox has its own implementation details, and Safari support has historically been spotty. The documentation around these edge cases tends to be sparse.
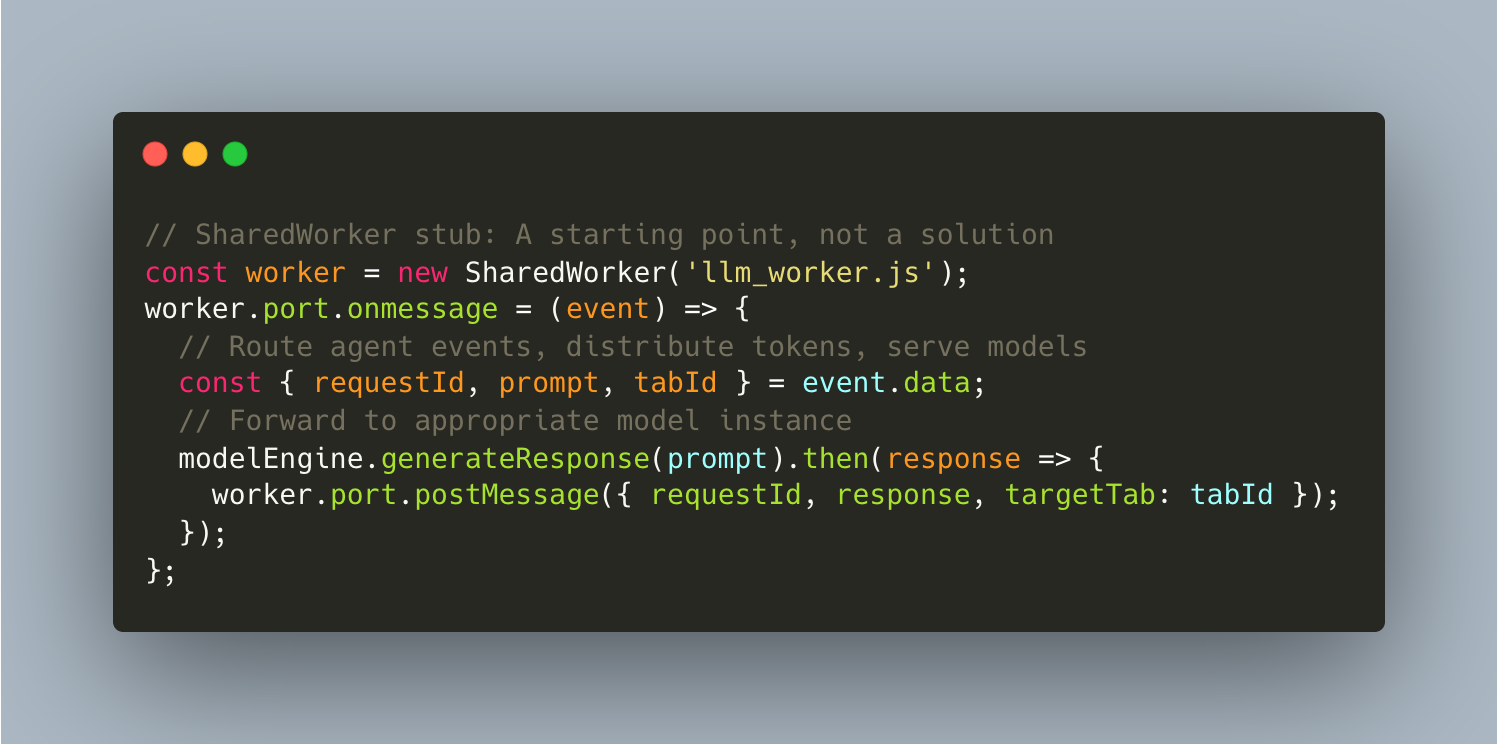
Implementation Considerations: Message routing patterns in SharedWorkers, including a pub/sub system where tabs subscribe to specific model instances, could help with organization. However, they might introduce race conditions that would be difficult to debug. When multiple tabs request inference simultaneously, coordination could become surprisingly complex.
Performance Considerations: GitHub's threading benchmarks suggest performance improvements when reusing workers versus spawning new ones. However, the single-threaded nature of SharedWorker execution could become a bottleneck for multi-model setups. Transferable Objects might help avoid serialization overhead, but transferring large model weights this way could prove challenging in practice.
Open Questions: How would one handle SharedWorker crashes gracefully? What about tab session management if one tab corrupts shared memory? How might one implement session-aware message routing so only the right tab gets the right inference result? And more practically: would this approach scale to many tabs, or is that just a theoretical benefit?
2. Advanced Model Caching: Promising in Theory, Complex in Practice
Browser storage mechanisms present interesting challenges for AI workloads. Each approach—service workers, Cache API, strategic eviction—has potential benefits but also limitations worth exploring.
Browser storage APIs offer various theoretical guarantees: Cache API for cross-session durability, Origin Private File System for file-system semantics, Storage Buckets for eviction control. Yet these guarantees might break down under real-world conditions. WebLLM's IndexedDB approach works for demos but could face challenges under the storage pressures of production applications. The practical limits may be lower than the theoretical ones.
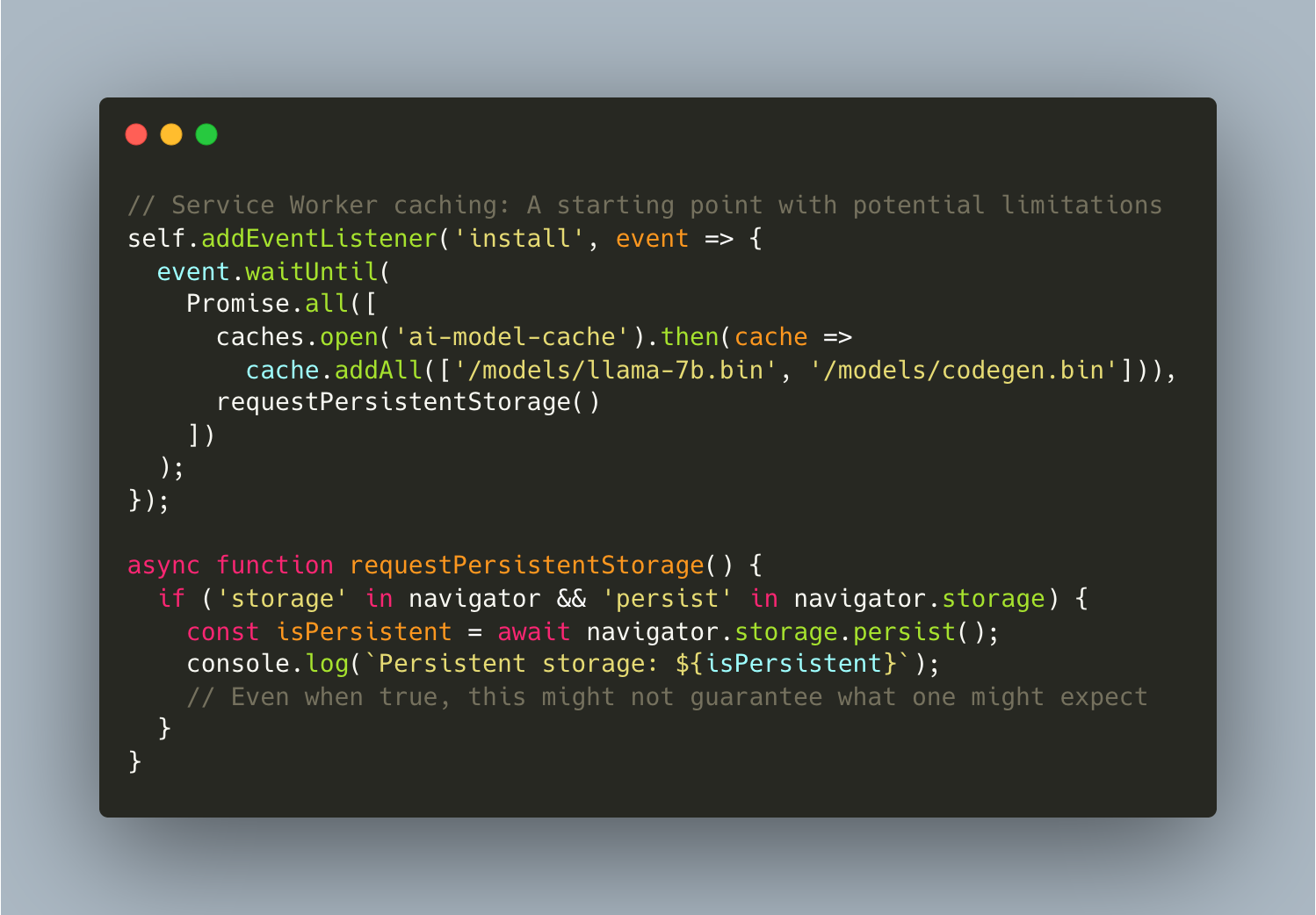
Caching Approaches to Consider: Multi-layered caching with LRU/LFU policies might work well in controlled environments, but browser storage limits could create hard ceilings. Semantic similarity-based caching based on recent research claiming 40-60% higher hit rates could be worth exploring, though storage quota issues might arise with larger datasets.
Storage Hierarchy Considerations: A tiered system (memory for hot models, Cache API for warm, IndexedDB for cold) with Background Sync for opportunistic downloads could be elegant in theory. But what happens when browsers reclaim cache storage? Recovery from eviction might create jarring user experiences that would be difficult to smooth out.
Research Questions: What reliable ways exist to track usage statistics across browser sessions? How consistent are browser storage quotas across implementations? How might Storage Buckets API behavior vary between browsers? More data on model caching reliability across browsers would be valuable for production applications.
3. JavaScript PubSub Event Bus: Conceptually Clean, Potentially Complex
Event-driven agent coordination through PubSub patterns looks elegant in diagrams but could become complex in implementation. While custom event-driven approaches might work for simple scenarios, they could introduce more complexity than they solve as agent interactions grow.
The apparent simplicity of browser-native PubSub is alluring: no external message brokers needed, no WebSocket overhead, just EventTarget APIs doing the work. Yet this approach might break down when event flows become complex or when circular dependencies emerge—both common scenarios in non-trivial agent systems.
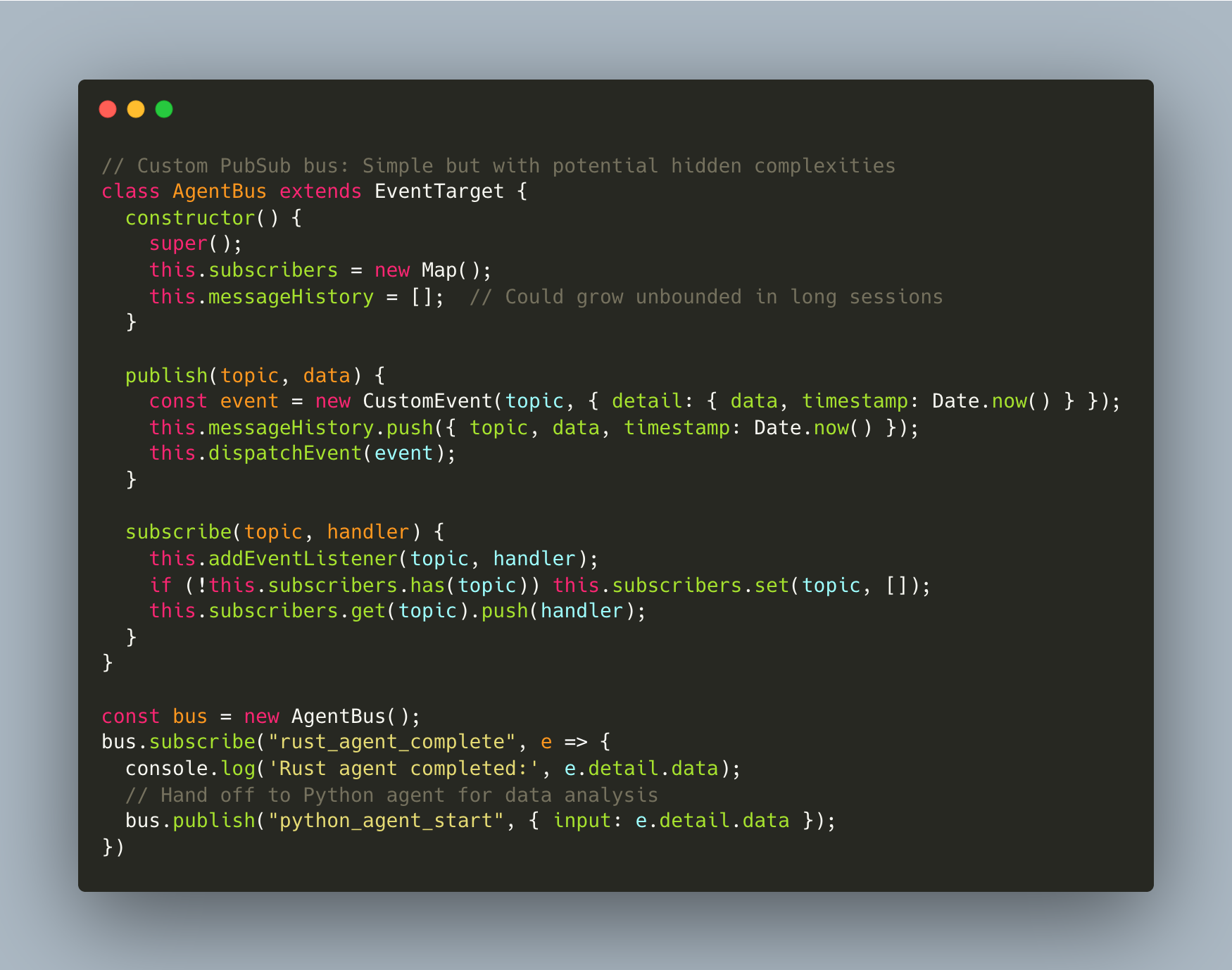
Cross-Language Considerations: Connecting agents in different WASM runtimes (Rust, Python, Go) through a central event bus could present challenges. Data format inconsistencies, serialization overhead between language boundaries, and memory management differences might create integration hurdles that pure JavaScript approaches wouldn't face.
Monitoring Complexity: Building telemetry for complex event flows could prove surprisingly difficult. Visualizing message patterns, detecting circular dependencies, and measuring handoff latencies might create additional complexity on top of the system being monitored.
Open Problems: How would one handle backpressure when subscribers can't keep up with event volume? What about message replay for failed operations? Would message history grow unbounded in long sessions, creating memory issues that could be difficult to address without losing potentially needed history?
4. Broadcast Channel API: Simpler Than Distributed Systems, But Different
The Broadcast Channel API enables cross-tab messaging, but there may be a fundamental mismatch between browser capabilities and distributed system requirements. While this API enables basic communication between tabs, it lacks the infrastructure typically associated with true distributed computing.
The Broadcast Channel operates on a simple pub/sub model with same-origin security, which helps with basic coordination. However, calling this a "distributed system" might oversell what's actually possible. It's perhaps more accurately described as a lightweight communication mechanism with its own set of limitations.
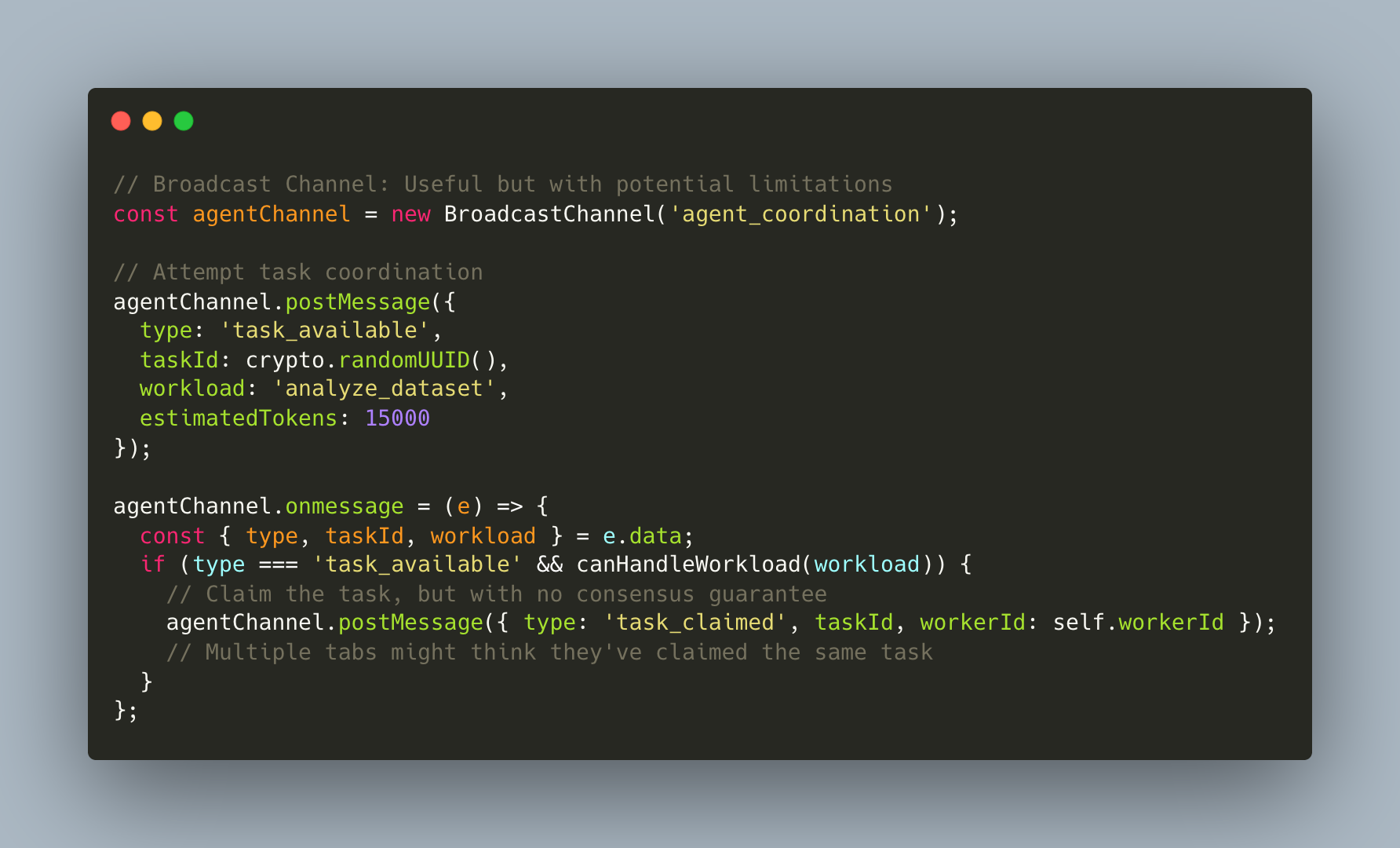
Distributed Coordination Challenges: Leader election protocols where one tab coordinates others might face fundamental challenges. When tabs claim tasks simultaneously, conflict resolution could become ad-hoc at best. Tab crashes and user-forced closures might orphan work units, requiring complex recovery logic that could potentially fail.
State Synchronization Considerations: Cross-tab state synchronization using timestamp-based conflict resolution might encounter edge cases that make consistency difficult to guarantee. Race conditions and split-brain scenarios that plague traditional distributed systems could appear in browser tabs too, often with fewer tools to address them.
Research Questions: How might one build reliable heartbeat mechanisms to detect crashed tabs? What would be the overhead of synchronization across many tabs? Most importantly, how could the fundamental reliability guarantees of true distributed systems (consensus, consistency, partition tolerance) be addressed in the browser context?
5. Background Model Management: Promising Direction with Potential Challenges
Background Sync API and Service Workers for model management offer interesting possibilities for smoother user experiences. However, browser limitations might create reliability challenges worth considering before implementation.
Background Sync offers a path to offline-first AI applications by queuing network operations for later execution. However, cross-browser implementations could be inconsistent. Mobile browsers in particular might aggressively kill background tasks, potentially leaving promised downloads incomplete.
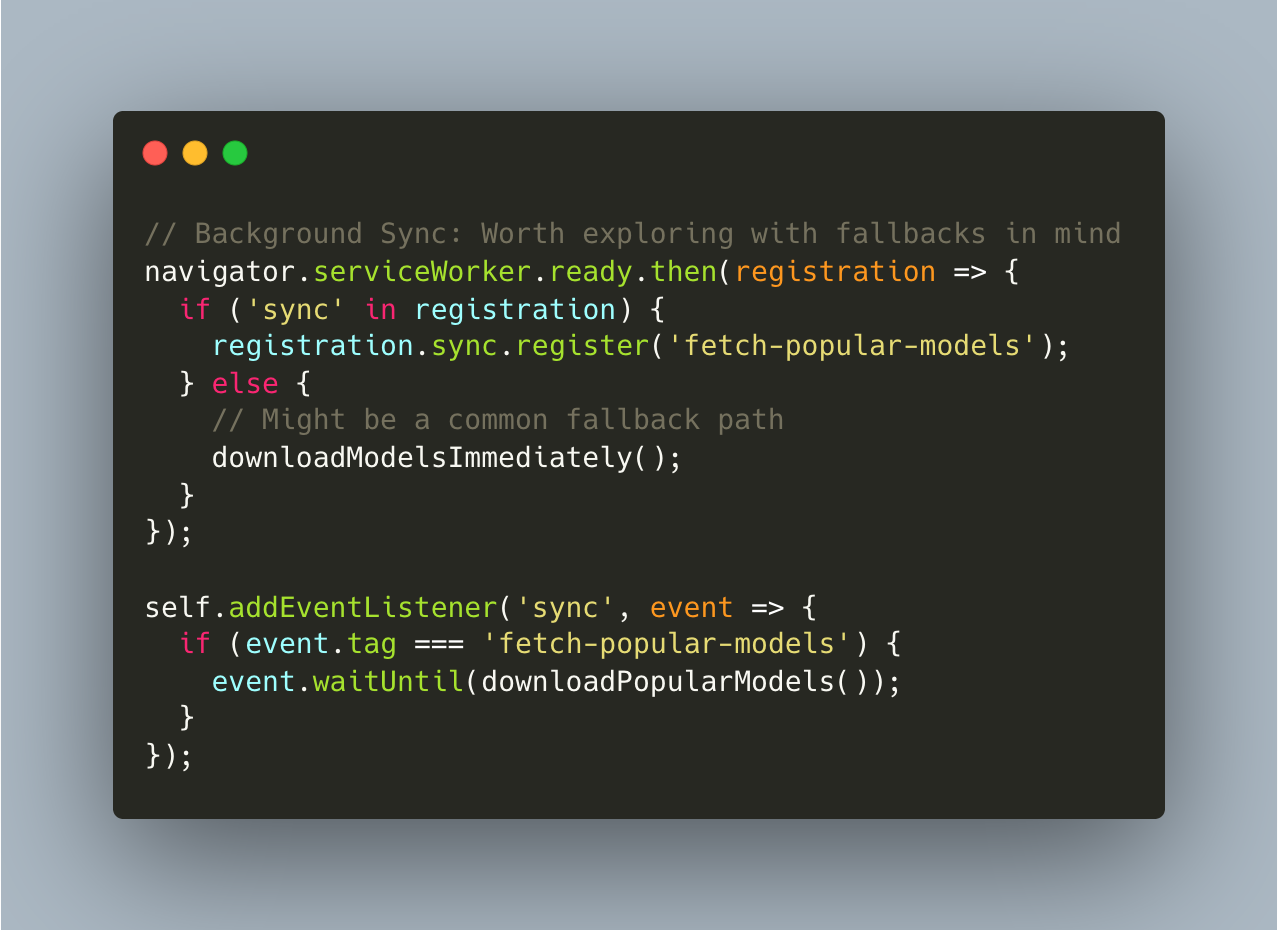
Predictive Loading Considerations: Building a system that attempts to predict which models users would need based on behavior patterns is intriguing, but would the accuracy justify the implementation complexity? Simpler heuristics might perform just as well without the overhead of sophisticated prediction systems.
Version Management Challenges: Managing model versions through background processes could create consistency issues. Users in mid-conversation when a model switched versions might be confused if response styles change. Defining reliable metrics to determine if a new model is "better" could prove surprisingly subjective.
Research Questions: How might systems handle cache storage quotas and unexpected eviction of carefully cached models? How consistent is Background Sync API behavior across browsers and operating systems? Even when background operations succeed technically, would the user experience always be improved?
6. AI-Native Browser Runtimes: Interesting Direction, Early Days
Both Lightpanda (an AI-first browser built in Zig) and Firefox's WebExtensions ML API represent interesting experiments. While both show potential, they might not be ready for production use beyond specialized scenarios. The gap between exciting demos and reliable tools could be substantial.
Lightpanda positions itself as a fundamental shift: a browser built from scratch in Zig, optimized for AI and automation. Their benchmarks show impressive performance improvements, but there might be substantial tradeoffs in web standards support and developer tooling. It represents an interesting research direction but possibly not a drop-in replacement for mainstream browsers yet.
Firefox's ML Platform (browser.trial.ml API) is an interesting step toward native model support, allowing extensions to run ONNX models directly with shared storage. It seems promising but appears limited in scope and still marked as experimental. Privacy implications of cross-origin model sharing warrant further exploration.
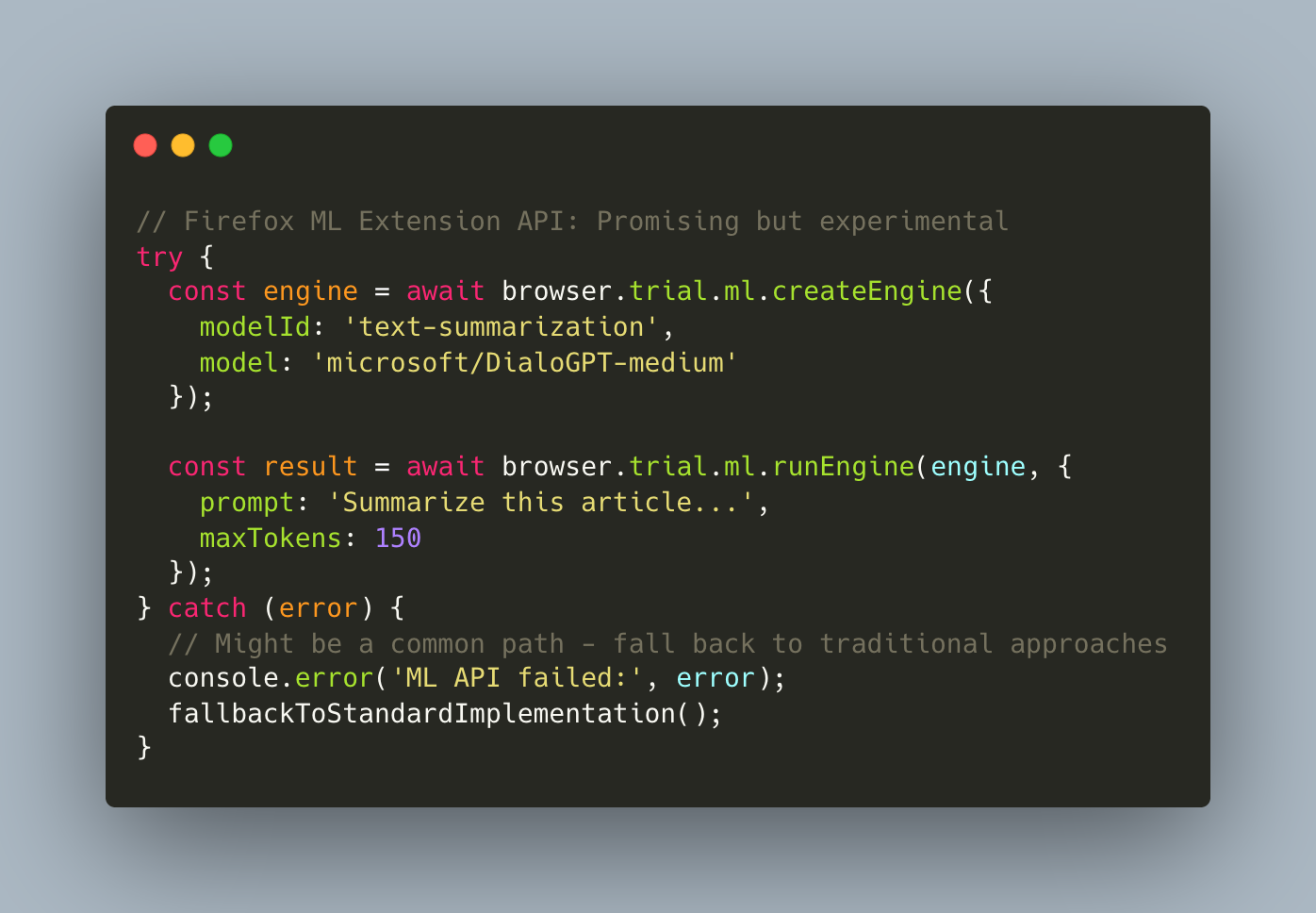
Architecture Considerations: Traditional browsers carry legacy code for rendering and UI, while AI-native browsers strip this away for performance. However, this might create significant tradeoffs in developer experience. Debugging tools, extension support, and standard web platform features could be missing or incomplete.
Experimental Status: These technologies represent interesting research directions rather than mature products. The trend toward AI-first browsers might eventually gain traction, but current implementations appear to be niche experiments with limited applicability beyond specialized use cases.
Research Questions: How mature are trial APIs for native inference? How might memory footprint comparisons in complex applications compare to simplified benchmarks? What tradeoffs in web standards compliance might create compatibility issues that could limit adoption potential?
7. Embedded JavaScript Engines: Interesting Architecture, Worth Evaluating
QuickJS and WasmEdge as embedded inference engines present an interesting architectural approach. The question remains whether the practical benefits justify the increased complexity for most applications.
QuickJS compiled to WebAssembly does indeed provide a complete JavaScript engine in a small package. It enables isolated execution contexts within a browser page, each running different agents. However, the operational complexity this introduces might create significant maintenance challenges.
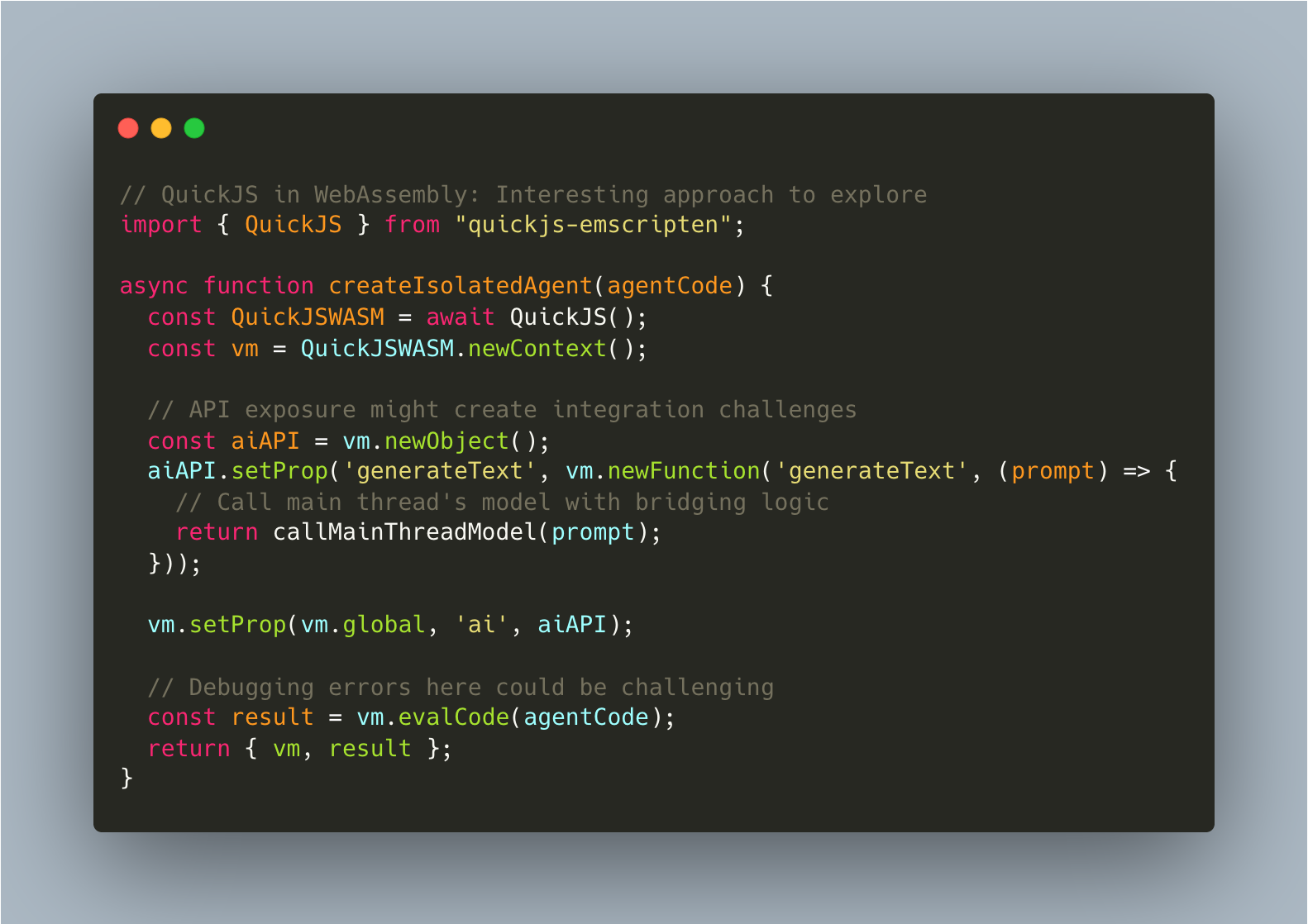
Isolation vs. Overhead: Running multiple agents in isolated contexts provides theoretical benefits for fault tolerance, but each context likely consumes additional memory. For many applications, it's worth questioning whether the isolation benefits justify the resource overhead.
Performance Questions: WasmEdge and QuickJS might show performance improvements in some scenarios, but would these be consistent across all workloads? The theoretical 2-3x gains could potentially be reduced in real-world applications with complex integration requirements and bridging overhead.
Research Areas: How difficult would debugging code running in isolated contexts be, with potentially limited tooling support and possibly opaque error messages? What performance overhead might cross-context communication add? How might version compatibility between engines affect maintenance burdens compared to simpler architectures?
8. In-Browser RAG Data Processing: Promising for Some Use Cases
DuckDB in the browser with vector similarity search extensions presents an interesting approach to local RAG (Retrieval-Augmented Generation). It likely performs well for small to medium datasets but may have scaling limitations that would make hybrid approaches necessary for larger applications.
DuckDB-Wasm appears to outperform many browser data processing libraries in synthetic benchmarks, with impressive speed improvements for analytical queries. However, when applied to real-world RAG scenarios with messy data and complex embedding structures, the performance advantages might narrow.
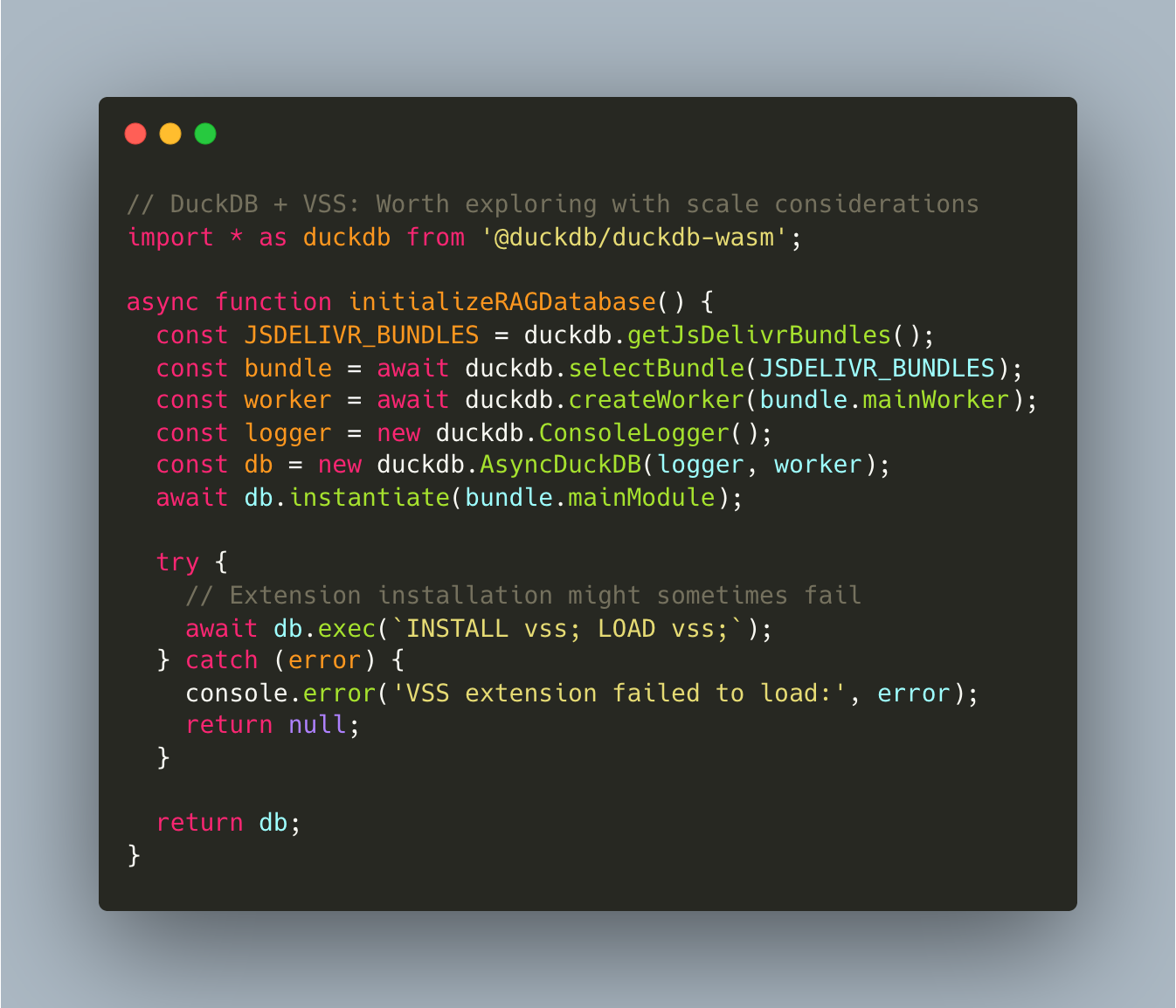
RAG Scale Considerations: Browser-based RAG implementations handling document chunking, embedding generation, vector storage, and retrieval client-side could work well for small document collections but might hit browser memory limits with larger datasets. The memory footprint of embeddings plus the RAG system could create practical ceilings lower than theoretical limits.
Performance Scaling Questions: While DuckDB-Wasm with PyArrow shows impressive speeds for small datasets, how might performance scale as vector stores grow larger? Memory constraints could potentially force paging to disk, causing latency spikes.
Hybrid Approaches: A hybrid approach—keeping frequently-accessed documents in browser storage while fetching others on-demand—could be promising. DuckDB's ability to query remote Parquet files could help bridge local and remote data, though determining the right balance between local and remote storage might require careful tuning.
9. Multi-Language Agent Playbooks: Interesting Research Direction
Browser-based notebook environments where different cells run agents in various languages (Rust, Go, Python, JavaScript) could create interesting research environments for comparative analysis. However, they might be too heavyweight and complex for typical development scenarios.
The concept is technically intriguing: running the same prompt through multiple language-specific agents and analyzing differences in quality, latency, and resource usage. However, the overhead might not justify the insights gained for most practical applications.
Value vs. Cost Assessment: This approach could enable systematic evaluation of different runtime approaches, measuring quality, efficiency, and scalability. However, loading multiple language runtimes creates substantial overhead that might make it impractical outside of research contexts.
Educational Potential: These tools might show promise as educational platforms, allowing developers to experiment with multi-language AI patterns without complex local setups. The visualizations and comparisons could provide valuable learning experiences, even if they aren't production-optimized.
Practical Questions: What would be the overhead of loading multiple language runtimes, even on high-end devices? How accurate would cross-language performance comparison be in the constrained browser environment? Would this reflect native performance characteristics accurately?
10. Memory Management Strategies: Necessary With Inherent Limitations
Browser memory management for AI models represents one of the more challenging areas to explore. While specific techniques might help reduce memory spikes, browser limitations fundamentally constrain what's possible compared to native applications.
Modern browsers provide some useful APIs but keep many aspects of memory management outside developer control. WebLLM applications do show memory spikes during model switching that could potentially be mitigated, but perhaps never fully eliminated within browser constraints.
WebAssembly Memory Considerations: Sharing model weights between WASM instances since weights are read-only during inference seems theoretically sound. However, current WASM limitations might make this approach challenging in practice, with memory addressing across contexts creating unexpected issues.
Simple vs. Complex Approaches: Would simple heuristics perform similarly to more complex prediction systems, with far less overhead? The theoretical elegance of ML-based memory management might not translate to practical benefits in browser environments.
Browser Constraints: Browser memory management has fundamental constraints to consider. Garbage collection timing remains largely outside developer control, pre-allocated buffers might be optimized away by browser engines, and browsers will likely reclaim memory regardless of careful management when system pressure demands it.
11. Progressive Loading: UX Promise with Technical Considerations
Progressive model loading—streaming weights in chunks and enabling partial functionality during loading—offers potential UX benefits but introduces technical complexity. Implementations might show promise but could face challenges in delivering consistent experiences across devices and network conditions.
The progressive UX transformation from "loading model..." to "getting smarter..." could appeal to users who prefer some functionality over waiting. However, implementing this consistently across browsers and network conditions presents challenges, with potential edge cases disrupting the experience.
Streaming Considerations: Using HTTP/2's multiplexing to stream model components in parallel, loading critical layers first, sounds promising. However, determining what's truly "critical" could be subjective, and handling interrupted streams or changing network conditions might create complex edge cases.
User Experience Questions: Would users indeed prefer functional degradation over loading screens, with basic models that respond quickly creating better initial experiences than waiting for perfect results? How challenging would it be to communicate capability changes without confusing users?
Technical Challenges: How consistent is bandwidth detection across browsers? How might progressive capability changes be communicated to users without confusion? Could partial models occasionally produce incorrect results due to limited context, creating trust issues?
Researcher's Assessment: Promising Directions Worth Exploring
Stepping back from these explorations reveals a field with both potential and significant questions that merit investigation.
Browser-native AI appears to be evolving beyond technical curiosities, with some approaches showing genuine promise for specific use cases. SharedWorkers, storage hierarchies, and background processing could eventually transform browsers into more capable compute platforms. However, there likely remains a gap between proof-of-concept implementations and production-ready systems, with browser limitations creating constraints on what's currently practical.
The architectural patterns explored here demonstrate interesting approaches to modularity and composition. Isolated runtimes, analytical databases, and cross-tab synchronization all have potential in specific scenarios. However, the increased complexity these approaches introduce should be weighed carefully against their benefits. In many cases, simpler architectures with fewer moving parts might prove more reliable in practice.
Browser-based agent systems represent an intriguing possibility rather than a current reality. Current implementations interface with models rather than enabling truly autonomous, tool-calling agents. While developments in Firefox's APIs, AI-focused browsers, and model capabilities suggest future potential, today's systems might be better viewed as early experiments rather than mature platforms.
Most importantly, each area explored here reveals substantial open questions. Memory management, multi-agent coordination, progressive loading, and distributed state coordination all present research questions worthy of further investigation. These represent fertile ground for continued exploration and experimentation.
The browser as an AI platform remains an intriguing possibility rather than today's reality. The most promising path forward likely involves hybrid approaches that leverage browser capabilities where appropriate while acknowledging their limitations. There's much to explore, experiment with, and discover in this emerging field.