Offline AI with Small Language Models: AI in the Browser


The field of artificial intelligence (AI) is evolving rapidly, with a growing emphasis on privacy, efficiency, and real-time processing. One of the most exciting developments in this space is the rise of Offline AI powered by Small Language Models (SLMs). Unlike traditional large language models (LLMs), which rely heavily on cloud infrastructure, SLMs are designed to operate efficiently on local devices, enabling AI capabilities without internet connectivity. This blog post explores the current state of offline AI with SLMs, its tools, technologies, real-world applications, and advanced performance optimization techniques like caching methodologies, Web Workers, IndexedDB, and WebGPU.
What Are Small Language Models (SLMs)?
Small Language Models (SLMs) are compact versions of large language models that are optimized for resource-constrained environments. These models are designed to perform natural language processing (NLP) tasks such as text generation, summarization, translation, and sentiment analysis while consuming significantly less computational power and memory.
The key advantage of SLMs lies in their ability to run locally on devices like smartphones, laptops, and even web browsers. This makes them ideal for offline use cases where privacy, latency reduction, or limited internet access is critical.
Why SLMs Over LLMs?
While LLMs like OpenAI’s GPT-4 or Google’s Bard offer immense capabilities, they often require significant computational resources and rely heavily on cloud infrastructure. SLMs provide a more lightweight alternative:
- Efficiency: SLMs are smaller in size and designed to run on devices with limited hardware capabilities.
- Privacy: Data remains on the device, ensuring sensitive information is not transmitted to external servers.
- Cost-Effectiveness: By eliminating cloud dependency, SLMs reduce operational costs for businesses.
- Accessibility: Offline functionality enables use in areas with poor or no internet connectivity.
Emerging Use Cases for SLMs
SLMs are increasingly being adopted for applications such as:
- Offline chatbots for customer support.
- Real-time translation apps that work without internet access.
- Browser-based AI tools for summarization and auto-completion.
- IoT devices like smart home assistants that process commands locally.
Transition to Optimization Techniques
As businesses and developers explore ways to integrate SLMs into their ecosystems, achieving optimal performance becomes a critical focus. The ability to deliver fast responses, handle complex tasks efficiently, and maintain a seamless user experience is essential—especially in resource-constrained environments like browsers or edge devices. To address these challenges, advanced technologies such as caching methodologies, Web Workers, IndexedDB, and WebGPU have emerged as powerful solutions. These approaches not only enhance the efficiency of offline AI systems but also unlock new possibilities for scalable and responsive applications.
With this context in mind, let’s dive into how these technologies can be leveraged to further optimize offline AI systems powered by SLMs.
Caching Methodologies for Offline AI
Caching plays a crucial role in improving the performance of offline AI systems by reducing redundant computations and speeding up inference times.
Here are some key caching methodologies relevant to SLMs:
- In-Memory Caching: Utilizes fast memory storage like RAM to store frequently accessed data, significantly reducing the time required for subsequent requests.
- IndexedDB: Provides a persistent key-value store that can be used to cache model outputs, embeddings, and other data structures.
- WebGPU: Offers hardware acceleration for complex computations, allowing for faster inference times.
- Web Workers: Enables parallel processing by offloading heavy computations to separate threads, improving overall performance.
These caching techniques not only enhance the efficiency of offline AI systems but also unlock new possibilities for scalable and responsive applications.
1. Key-Value (KV) Caching in Browsers
Key-Value (KV) caching stores intermediate results from the attention mechanism during token generation. It significantly reduces computational overhead by reusing previously computed key-value matrices for subsequent tokens.
How KV Caching Works in Browser-Based SLMs
During inference, transformers compute key (K) and value (V) matrices for each token. These matrices are stored in memory as a KV cache. When generating subsequent tokens, the model retrieves K and V from the cache instead of recalculating them.
Practical Implementation in Browsers
In browsers, KV caching can be implemented using JavaScript’s Map or WeakMap objects to store token-specific K-V pairs:
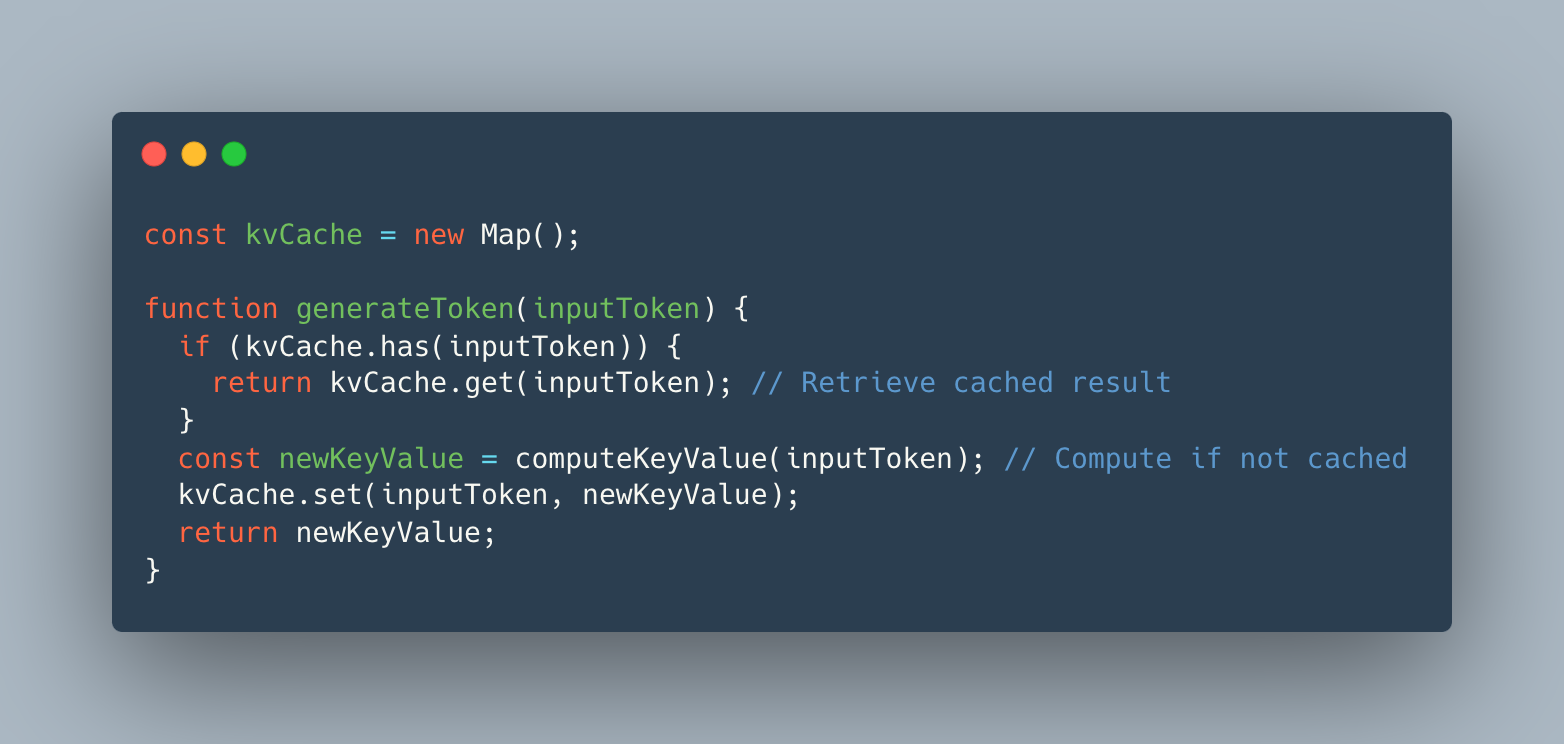
This approach ensures that frequently used tokens (e.g., common words or phrases) are processed faster, improving response times for browser-based SLMs.
Prompt Caching in Browsers
Prompt caching involves storing precomputed embeddings or attention states for frequently used prompts. This technique is particularly useful for repetitive tasks like form auto-completion or template-based responses.
How Prompt Caching Works in Browsers
- During the first interaction with a prompt, its embeddings or attention states are computed and stored in a cache.
- For subsequent interactions with similar prompts, the cached data is retrieved instead of recomputing everything.
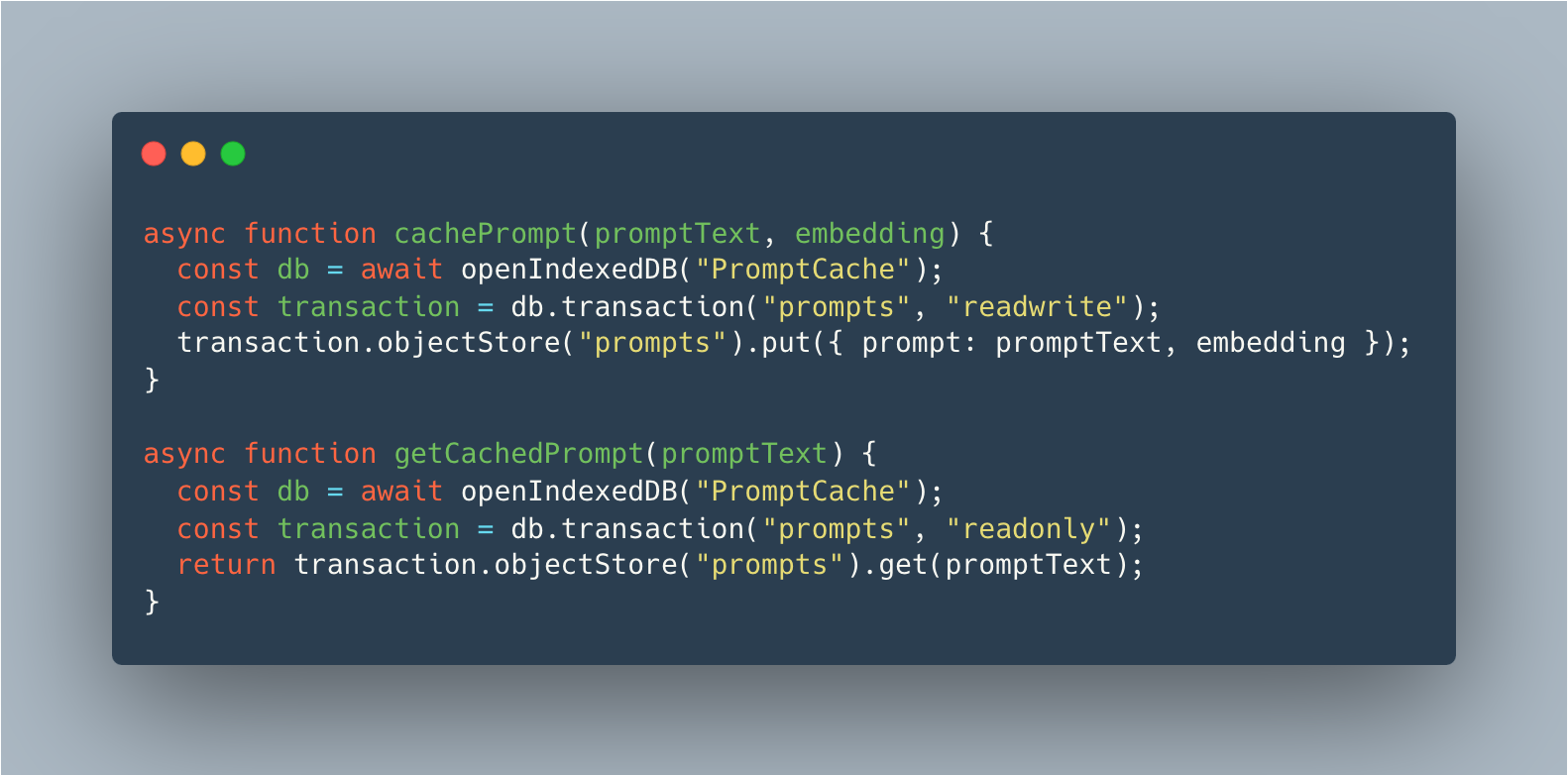
This setup allows preloading frequently used prompts into the browser’s local storage for quick reuse.
2. WebGPU Acceleration for Fast Inference
WebGPU is a next-generation graphics API that allows browsers to access GPU resources directly. For offline AI systems using SLMs:
- WebGPU accelerates matrix multiplications during inference.
- It reduces latency by leveraging parallel processing capabilities of GPUs.
Practical Implementation in Browsers
To implement WebGPU acceleration, developers need to:
- Create a WebGPU context and configure the GPU device.
- Load the SLM model and prepare it for inference.
- Use WebGPU shaders to perform matrix multiplications efficiently.
This approach significantly enhances the performance of offline AI systems, allowing for faster inference times and improved user experience.
For example:
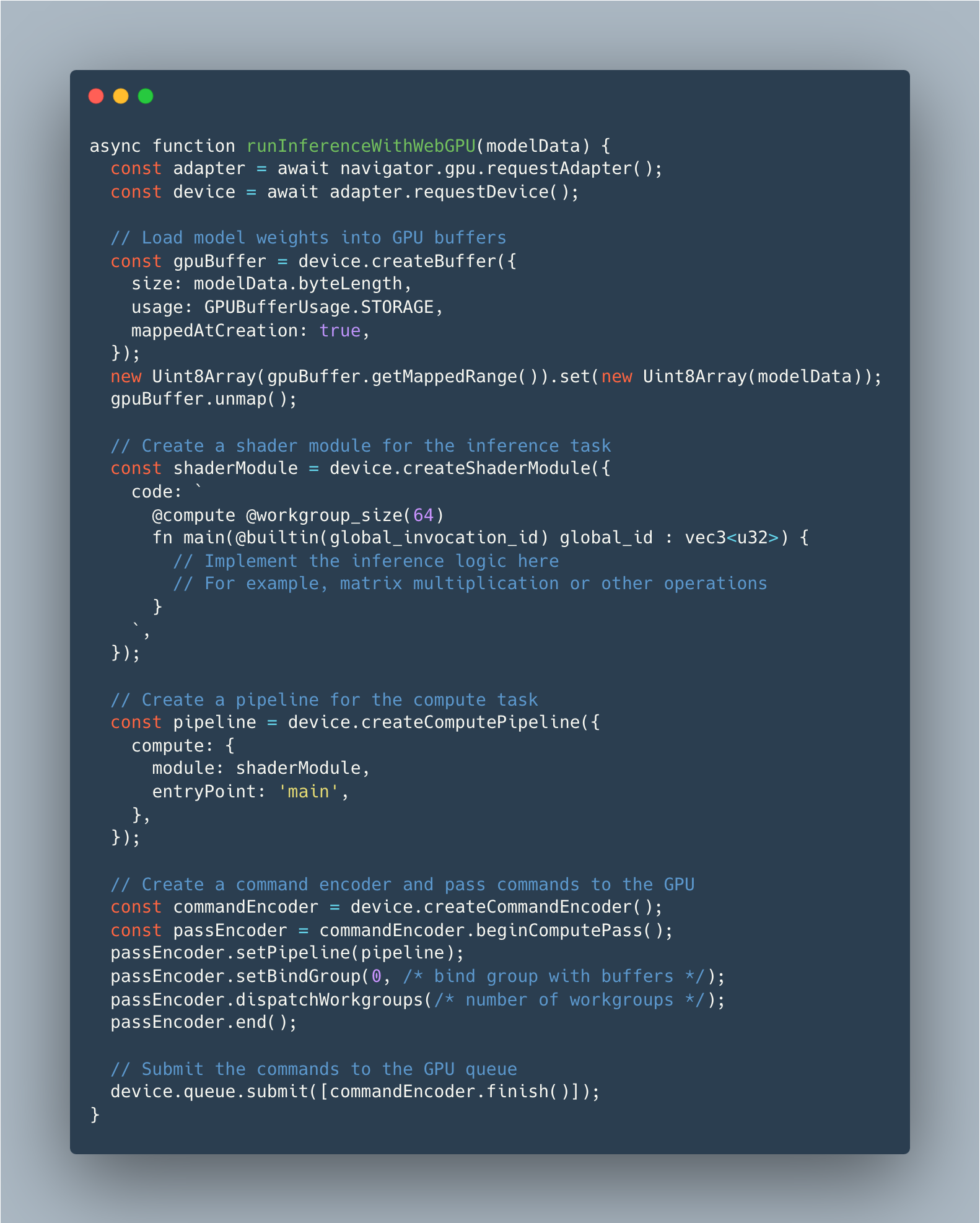
I know this is a bit complex but it's a good example of how you can use WebGPU to accelerate the inference of an SLM directly in the browser. But also you need to consider if your local browser is supporting WebGPU or not. You can check it out here: WebGPU Report.
By integrating WebGPU into browser-based SLM workflows, developers can achieve near real-time performance even on resource-constrained devices.
Combining Caching & Advanced Technologies: Retail Use Case
Imagine a retail company that wants to deploy an offline AI-powered chatbot to assist employees and customers in-store. The chatbot is designed to handle queries such as checking inventory, providing product recommendations, and answering frequently asked questions—all without relying on internet connectivity. To achieve optimal performance, the company leverages a combination of advanced technologies: WebGPU acceleration, IndexedDB caching, Web Workers, and Key-Value (KV) caching.
System Overview
The offline chatbot system is designed with the following components:
- WebGPU Acceleration: Accelerates inference tasks by leveraging GPU resources for matrix operations.
- IndexedDB Caching: Stores product data, FAQs, and precomputed embeddings locally for quick access.
- Web Workers: Offloads computationally intensive tasks like token generation and query processing to background threads.
- Key-Value (KV) Caching: Reuses intermediate results during token generation to reduce redundant computations.
Implementation Details
- WebGPU Acceleration: The chatbot uses WebGPU to accelerate matrix multiplications during inference. This allows for faster processing times and improved user experience.
Example Workflow:
When a user asks, “Is Item X available in stock?”, the chatbot processes the query by running it through the SLM. WebGPU accelerates key operations like attention mechanism calculations and embedding lookups, ensuring near real-time responses.
- IndexedDB Caching: The chatbot stores product data, FAQs, and precomputed embeddings locally in IndexedDB. This enables quick access to frequently used data, reducing latency and improving response times.
What’s Cached?:
-
Product details (e.g., names, SKUs, prices).
-
Frequently asked questions (FAQs) and their precomputed embeddings.
-
Historical user queries and responses for personalization.
-
Web Workers: The chatbot offloads computationally intensive tasks like token generation and query processing to background threads using Web Workers. This allows for parallel processing and improved overall performance.
How Web Workers Fit In:
- When a user submits a query, it is sent to a Web Worker responsible for running the SLM inference.
- The worker processes the query asynchronously and sends back the result to the main thread for display.
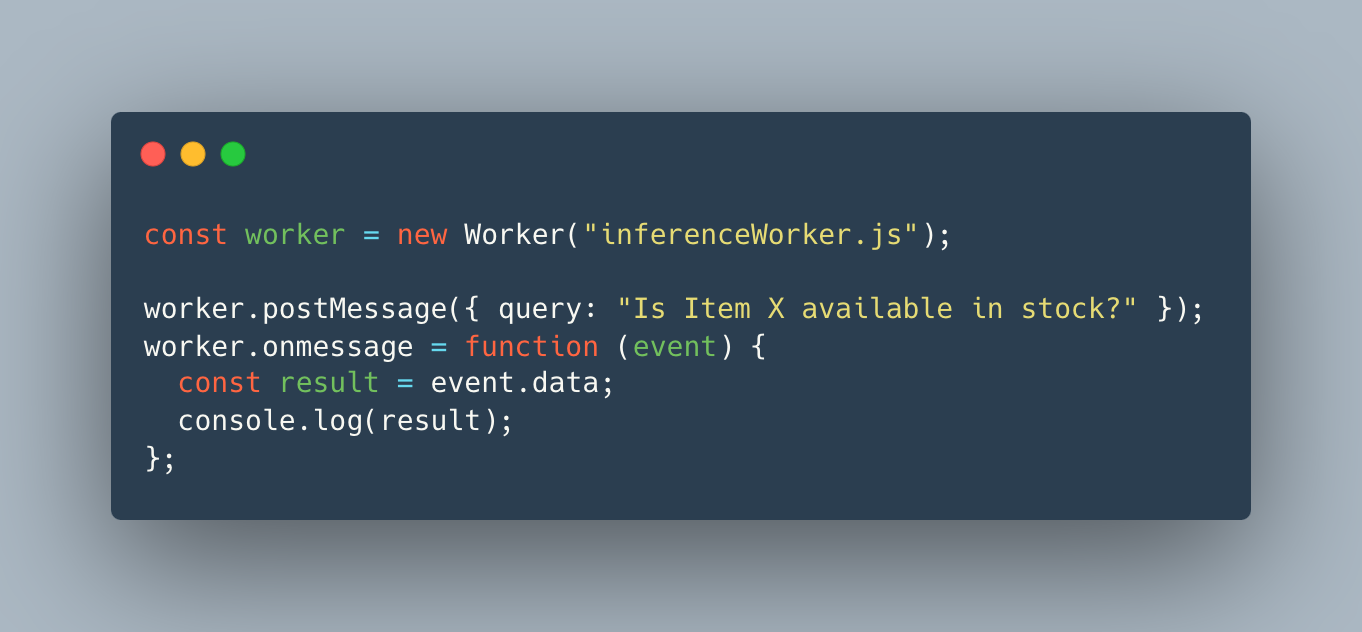
Parallelizing Tasks with Multiple Web Workers
You can even use different files for splitting up the tasks into different workers based on the task and the core number of the machine the SLM is running on:

- Key-Value (KV) Caching: The chatbot uses KV caching to store intermediate results from the attention mechanism during token generation. This reduces redundant computations and speeds up inference times.
How KV Caching Works in This Use Case:
- When generating a response to a query like “Is Item X available?”, intermediate results from earlier tokens are cached.
- For subsequent tokens in the same response, cached values are reused instead of recomputing them.
End-to-End Workflow
Here’s how all these technologies come together in this retail use case:
- A customer asks: “Do you have Item X in stock?”
- The main thread sends this query to a Web Worker.
- The Web Worker runs the SLM inference using WebGPU acceleration for faster processing.
- The system checks IndexedDB for cached product data related to Item X.
- If found, it retrieves details like SKU number and availability status.
- If not found, it computes or fetches data locally and stores it in IndexedDB for future use.
- KV caching ensures that intermediate results from token generation are reused during response creation.
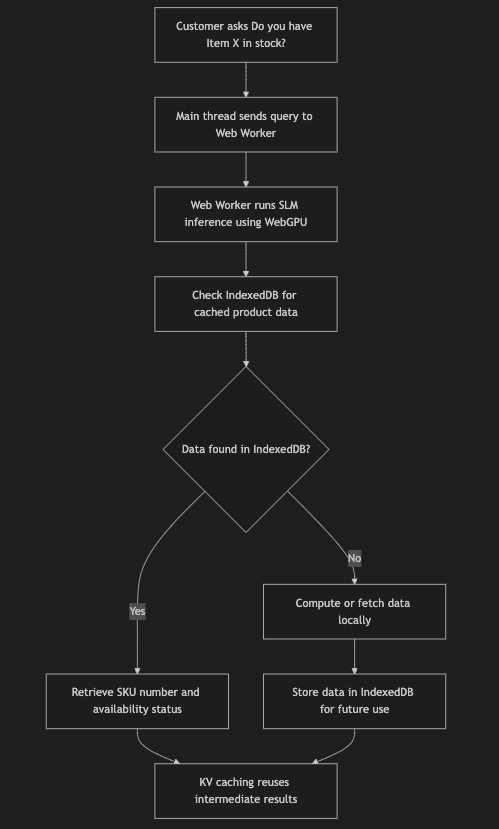
The final response is sent back to the main thread and displayed to the customer via an intuitive chatbot interface.
Benefits of This Approach
- Reduced Latency: WebGPU acceleration ensures fast inference even for complex queries.
- Improved Responsiveness: Web Workers prevent UI freezing by handling heavy computations in parallel threads.
- Data Availability: IndexedDB caching ensures that frequently accessed data is always available offline.
- Resource Efficiency: KV caching minimizes redundant computations, optimizing performance on edge devices.
This architecture not only enhances operational efficiency but also provides a seamless experience for both employees and customers—making it an ideal solution for retail environments where reliability and speed are critical.
Conclusion
By leveraging technologies like caching methodologies (KV/Prompt Caching), Web Workers, IndexedDB storage mechanisms, and WebGPU acceleration alongside Small Language Models (SLMs), businesses can build efficient offline AI systems tailored to their needs—ideal for industries like retail or manufacturing where reliability is paramount!